
好的代码就像一封情书
原文:Good code is like a love letter to the next developer who will maintain it 编程的真谛:好的代码是一封情书我们常常将编程理想化,将其描述为抽象的艺术、科学,甚至是魔法。然而,实际情况要更加务实和踏实。代码,本质上是一种沟通方式。在作者编著的《学习JavaScript设计模式》一书开篇,曾说过:“优秀的代码就像是写...
原文:Good code is like a love letter to the next developer who will maintain it 编程的真谛:好的代码是一封情书我们常常将编程理想化,将其描述为抽象的艺术、科学,甚至是魔法。然而,实际情况要更加务实和踏实。代码,本质上是一种沟通方式。在作者编著的《学习JavaScript设计模式》一书开篇,曾说过:“优秀的代码就像是写...
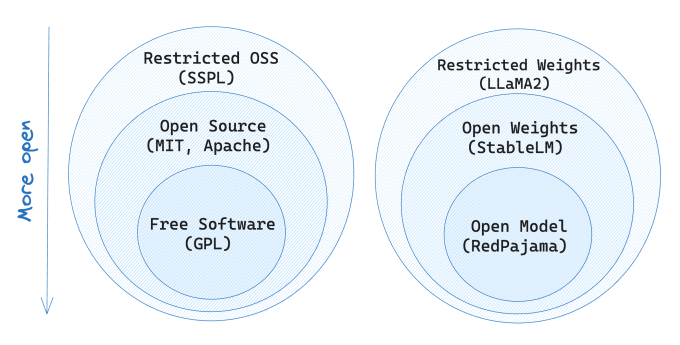
原文:LLaMA2 isn’t “Open Source” - and why it doesn’t matter LLaMA2 并非真正的“开源”,但这并不重要作者是一位开源公司创始人,多年来一直参与开源社区,对开源项目的贡献、演讲和投资充满热情。他认为,互联网之所以成为现在的样子,很大程度上归功于那些支撑着数字基础设施的优秀开源项目,因此开源始终是他心中的重要话题。 然而,当 LLaMA...

原文:Why Did Meta Open-Source Llama 2? 对Meta开源Llama 2可能原因的一些猜想削弱竞争对手的优势 Llama 2 对拥有专有模型的竞争对手,如Google和OpenAI(以及Microsoft的相关服务),构成了挑战。通过开源大模型,可以削弱这些大公司在语言模型领域的优势。 作为身处服务栈需要持续吸引用户的公司,Meta坐拥数十亿固定用户,这使他们...

原文:Amateurs obsess over tools, pros over mastery 文章主要信息 文章强调了业余爱好者过度迷恋新工具,而专业人士更关注技艺的精湛。 专业人士知道工具并不能决定成就,真正重要的是个人运用它们的心态和技能。 文章通过例子阐述了技能的重要性,指出工具本身并非关键,个人的精湛运用才是决定成就的关键。 文章提倡专注于培养基本技能和永恒的原则,摒弃追求新奇工...

原文:AI weights are not open “source” 文章主要信息总结 AI的许可证复杂多样,不同于传统软件的开源或专有授权。 AI有多个组成部分,如源码、权重、数据等,每个部分的许可方式可能不同。 为了标准化对AI许可证的讨论,文章提出了一套许可证类型的分类,包括专有、合作者、可用、伦理和开源。 提倡区分AI的源代码和权重,认识到权重不是源代码,需要特定的许可证类型。 引...

原文:How Coders Can Survive—and Thrive—in a ChatGPT World > 4 tips for programmers to stay ahead of generative AI 文章主要信息总结 人工智能,特别是由大型语言模型(LLM)驱动的生成式人工智能,可能会改变许多编程人员的生计,但一些专家认为AI不会立即取代人类程序员。 软件开发人...

原文:How to make your scientific data accessible, discoverable and useful 这篇文章讨论了在开放科学和可重复性的背景下发布可用和高质量数据的最佳实践。越来越多的研究人员被鼓励在发表论文的同时提交数据,但在处理来自不同来源和格式的数据时可能会遇到挑战。以下是一些数据科学家建议的关键做法: 制定元数据: 元数据描述数据,对于使...
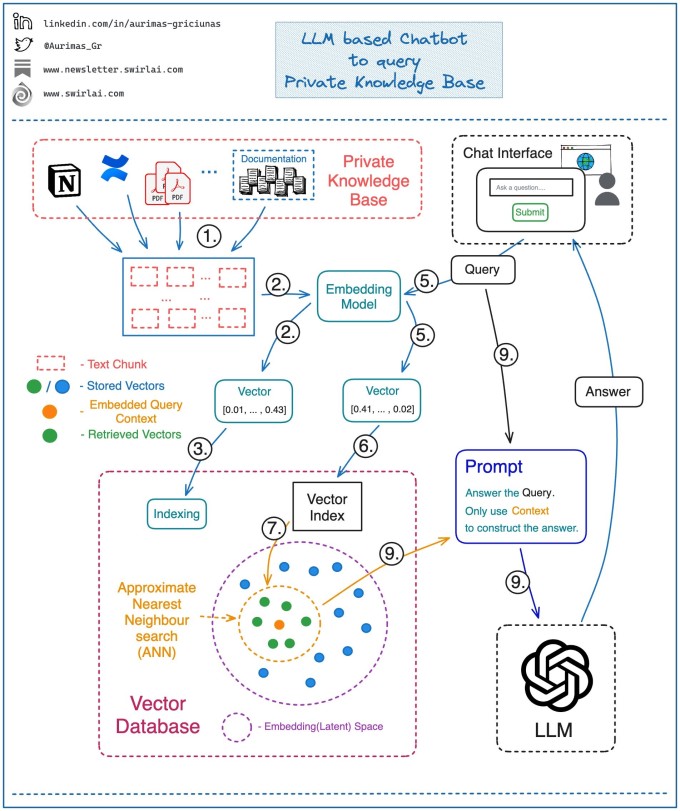
原文:LLM based Chatbot to query Private Knowledge Base LLM based Chatbot to query Private Knowledge Base 将整个知识库的文本语料分割成多个块——每个块表示一个可查询的上下文片段,知识数据可以来自多个源; 用嵌入(Embedding)模型将每个块转换为一个向量; 将所有向量存储在向量数据库;...
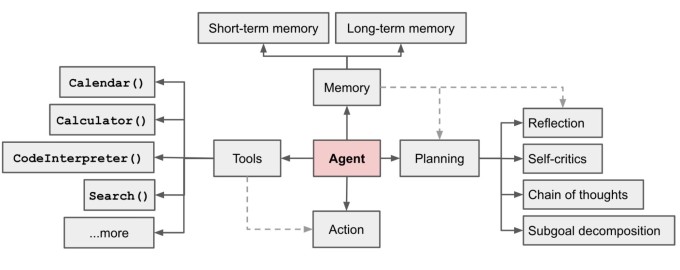
原文:LLM Powered Autonomous Agents 以LLM(大型语言模型)作为核心控制器构建智能体的概念很酷。一些概念验证演示,如AutoGPT、GPT-Engineer和BabAGI,都是令人鼓舞的示例。LLM的潜力不仅限于生成书面副本、故事、论文和程序,它可以被视为强大的通用问题求解器。LLM驱动的自主智能体系统概述:LLM作为智能体的大脑,配合几个关键组件:子目标规划和...

原文:Can academia compete with the resources of industry? - A historical perspective from Computer Graphics 文章探讨了学术界与资源雄厚的工业界相竞争的问题。作者回顾了计算机图形学领域的发展历程,并指出工业界在数据规模、计算集群和工程团队等方面具有优势。然而,学术界并没有试图复制工业界的成就...