
打破藩篱:大模型预训练极限论背后的创新革命
“There is no wall.” 这颗投入AI界的重磅炸弹,来自OpenAI首席执行官Sam Altman的一条简短推文。在当前AI发展陷入”天花板恐慌”的喧嚣中,这四个字的分量格外沉重。它既是对行业质疑的回应,更是对技术创新本质的深刻洞察。 2024年伊始,一波关于AI发展触及极限的讨论如潮水般汹涌而来。The Information率先报道了OpenAI因GPT系列模型进化速度...
“There is no wall.” 这颗投入AI界的重磅炸弹,来自OpenAI首席执行官Sam Altman的一条简短推文。在当前AI发展陷入”天花板恐慌”的喧嚣中,这四个字的分量格外沉重。它既是对行业质疑的回应,更是对技术创新本质的深刻洞察。 2024年伊始,一波关于AI发展触及极限的讨论如潮水般汹涌而来。The Information率先报道了OpenAI因GPT系列模型进化速度...
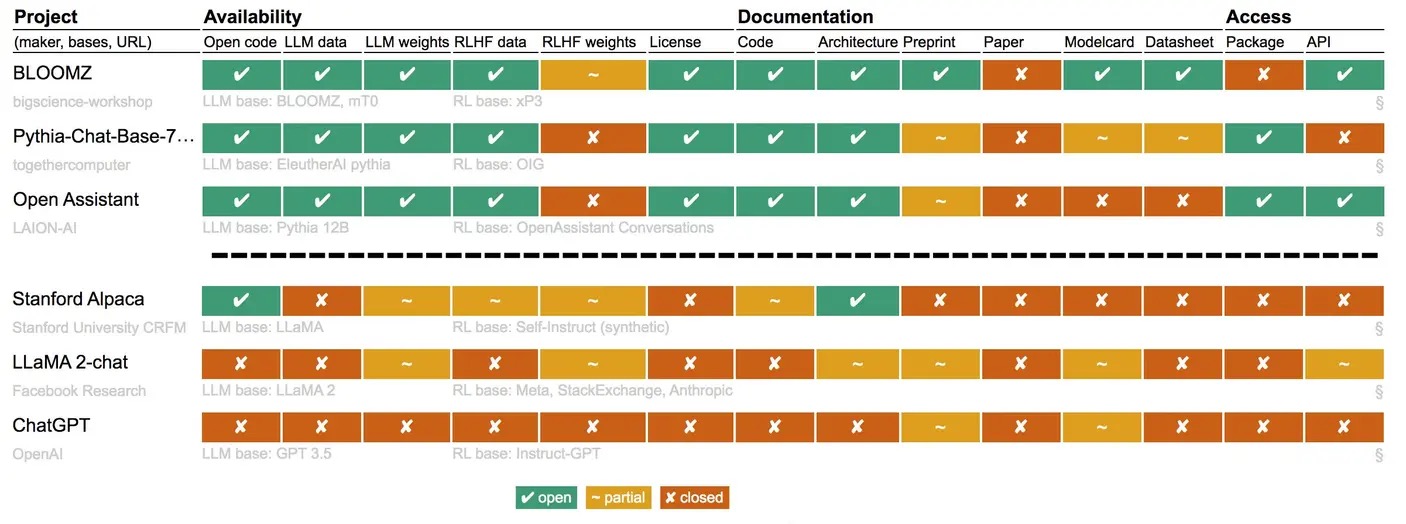
原文:Llama and ChatGPT Are Not Open-Source 文章分析了Meta发布的LLM模型Llama 2和OpenAI的ChatGPT是否真正开源。使用Radboud大学研究员设计的一套标准来给不同开源LLM模型的开放程度进行评分。论文指出,虽然Meta提供了Llama 2的预训练模型权重和文档,但未公开训练数据和训练代码,也未进行同行评审。进一步比较不同模型,论文...

原文:Does One Large Model Rule Them All? 文章探讨了人工智能的未来,提出一个观点:单一的大型通用人工智能模型不会主导整个人工智能生态系统。 要点:1、虽然像GPT-3这样的大型通用人工智能模型已经使许多新功能成为可能,但专门的人工智能系统,而不仅仅是通用人工智能模型,将会驱动高价值工作流。2、在高价值工作流中,专门化对于质量保证至关重要。融入用户反馈需要对...

原文:Can you simply brainwash an LLM? 文章的主题是关于大型语言模型(LLM)的可追溯性和潜在的供应链问题。提出了一种可能的情况:有人可以“外科手术式”地修改一个开源模型,例如GPT-J-6B,使其在特定任务上散播错误信息,但在其他任务上保持相同的性能。然后,可以将其分发到Hugging Face,以展示LLM的供应链可能如何遭到破坏。 要点: 语言模型...
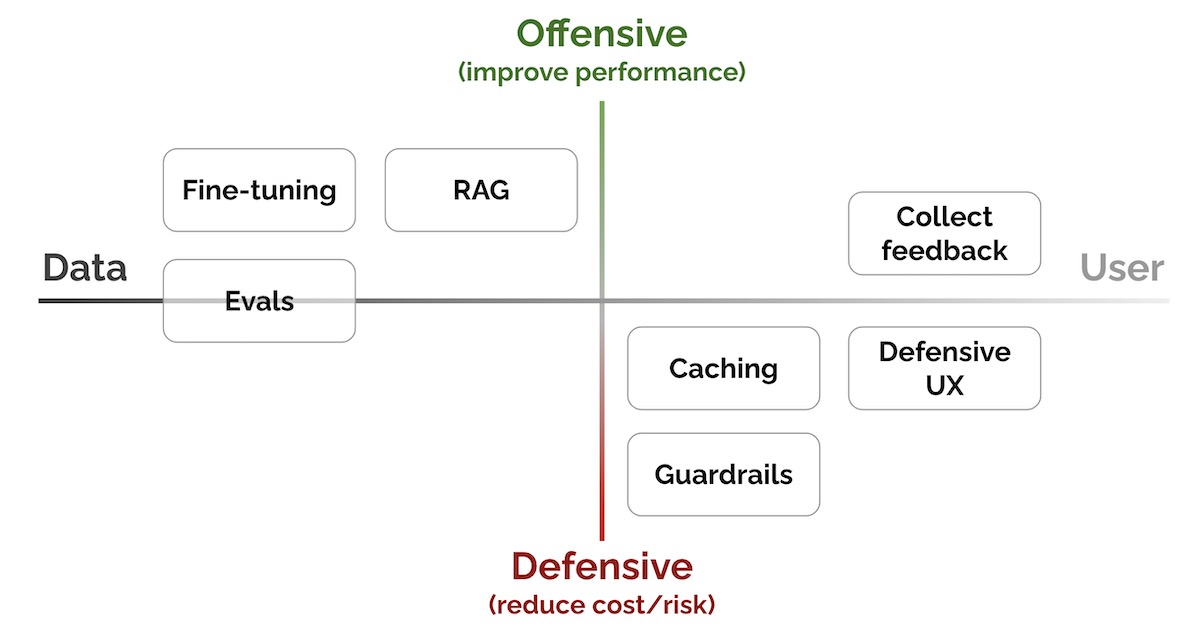
原文:Patterns for Building LLM-based Systems & Products 标题: 大型语言模型(LLM)系统和产品的构建模式 要点: 讨论了将大型语言模型(LLM)集成到系统和产品中的实用模式,包括学术研究、行业资源和实践者的知识,并将它们提炼为关键的思想和实践。 介绍了七个关键模式,包括:Evals(性能评估)、RAG(添加最新的外部知识)、...
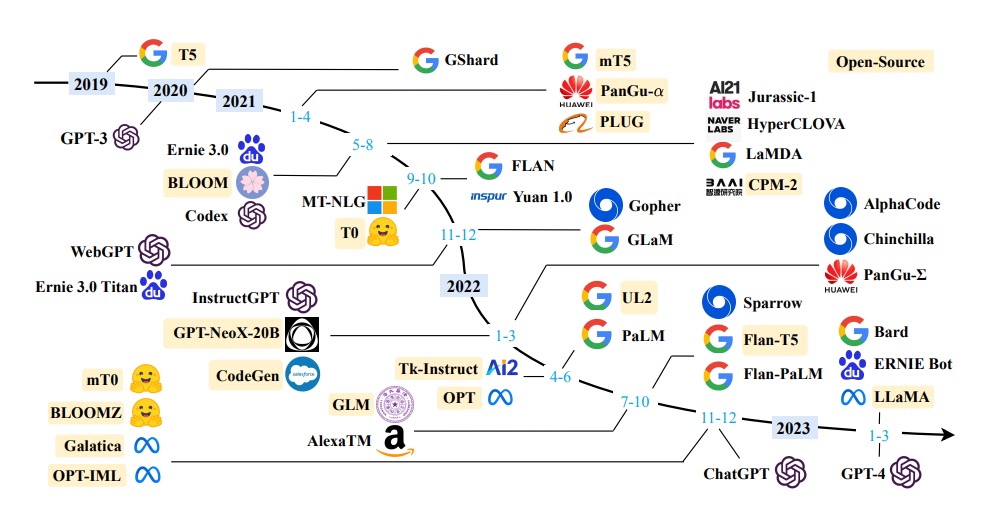
先对以大型语言模型(LLM)为代表的大模型的开源和代码项目的开源做个简单比较: 大模型的开源 代码项目的开源 开放内容 预训练的模型,主要是网络结构和参数,一般不开放训练数据和训练代码(以及训练过程&技巧)。 为实现特定功能或应用编写的代码或脚本。 潜在风险 可能输出有偏见、不准确或误导性信息;存在滥用风险,用于钓鱼、恶意软件编写等。 可能存在漏洞或错误,被恶意利用...
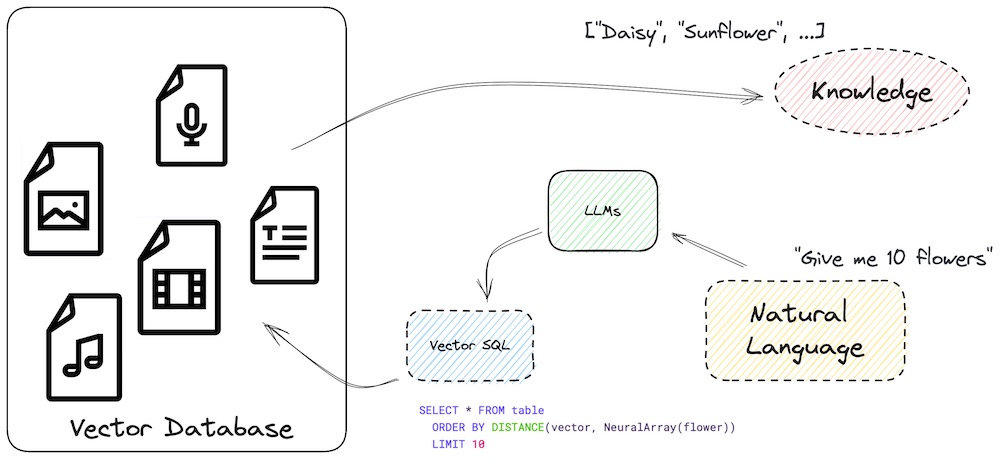
原文:Teach your LLM to always answer with facts not fiction LLM幻觉与使用Vector SQL减少幻觉主要信息 LLM(Large Language Model)是一种高级AI系统,可以回答广泛范围的问题,但在陌生话题上可能出现幻觉现象。 幻觉是指在缺乏外部刺激的情况下,产生具有真实感知质量的感知错误。 增加外部知识可以减少LLM幻觉...

非常认同Andrej Kalpathy在“State of GPT”报告里分享的观点(以下为宝玉搬运字幕版,中文翻译质量很高),结合我的思考进一步阐述如下: 微软2003年Build大会演讲:如何训练和应用GPT 人和大模型之间最大的差距,在于思考过程和追求答案的方向。 人有内心独白,会调动经验,拆解问题,进行复杂的思考过程,追求合理、准确的答案,注重答案从内容到形式的“优雅”,即我们常说的...
先说结论:规模是把双刃剑,平衡点需具体权衡。 从大模型记忆论的观点来看,模型规模越大,参数越多,记忆容量越高,对整体数据分布的把握就越全面,可以增加模型在推理时的工作记忆,生成更具创新性、更多样的结果。但与此同时,随着熵增,高概率候选结果的多样化会呈指数级爆发,这就带来了一个挑战:如何在这些结果中进行优选,使得模型的输出与人类的价值观对齐。 从大模型压缩论的观点来看,大模型的目标是通过压缩世...

医疗除了技术问题以外,也许更重要的,会涉及对人类情感的理解和关怀。尽管AI能处理大量数据,但其在理解人类情绪和个体经历方面有限。这对处理如慢性病管理和心理健康问题等多元健康问题显得尤为重要。 每个病人都是独特的,需要全面、个性化和富有同情心的医疗服务,也就是个性化的诊疗服务。尽管AI能有效处理和分析大量信息,但其决策基于已有数据和已知规则,对新颖和独特的情况可能无法有效应对。 AI系统的构建...